Linux
-
MX-Linux también rechaza un sistema de verificación de edad en Linux
En su último informe semanal, MX-Linux se ha posicionado también en contra de la nefasta implementación del protocolo de verificación de edad en systemd que lleva causando reacciones este mes. “Nadie en el equipo de MX quiere implementar algo como una verificación de edad”, dicen en su nota. Pero también mencionan que nadie quiere implementar
-
VitruvianOS: ¿el regreso de BeOS?
En redes y foros hoy se está hablando de VitruvianOS (o simplemente v-OS). Es un sistema operativo salido de la nada pero que, según su página web, ejecuta un núcleo Linux en tiempo real junto con una capa de compatibilidad llamada Nexus, que lo vuelve compatible con BeOS, un viejo sistema operativo de finales de
-
Linux 6.12 ya disponible
Este fin de semana ha salido el kernel Linux versión 6.12. ¿Qué hay de nuevo? Bueno, tienes el anuncio escrito por Torvalds, pero si al igual que la mayoría de nosotros, no lo entiendes, y te has cansado de aparentar como que no pasa nada, este es un resumen de lo más destacado que se
-
¿Debe la cuenta root de una instalación GNU/Linux tener su propia contraseña?
Hoy en día, lo normal es que el procedimiento de instalación de muchas distribuciones GNU/Linux traten la cuenta que creas durante la instalación, por ejemplo, esa que creas cuando te pregunta cómo te llamas y cuál quieres que sea la contraseña de tu cuenta personal, como una cuenta administradora. Esta cuenta es normal, como cualquier
-
¿Para qué sirve Docker?
Quizá hayas escuchado hablar de Docker alguna vez. Se trata de una tecnología que promete permitir ejecutar aplicaciones y programas de ordenador en un lugar conocido como contenedor. A menudo lo usan para ejecutar aplicaciones de red que se ejecutan en servidores, pero en realidad puedes usarlo en tu propio ordenador personal para instalar programas
-
La secuencia de As y Bs que se convirtió en Linux
Mirando por los mastodones, me encuentro este artículo un poco antiguo de LWN, donde uno de los compañeros de universidad de Linus Torvalds, que estuvo también ahí para ver nacer Linux, comparte cómo eran los primeros días. Lo que posteriormente se convirtió en Linux nació como un programa pequeño hecho para un primitivo sistema 386.
-
passwd: todo lo que debes saber
Un tutorial para poder utilizar el comando passwd que puede ayudar a las personas que recién llegan a UNIX.
-
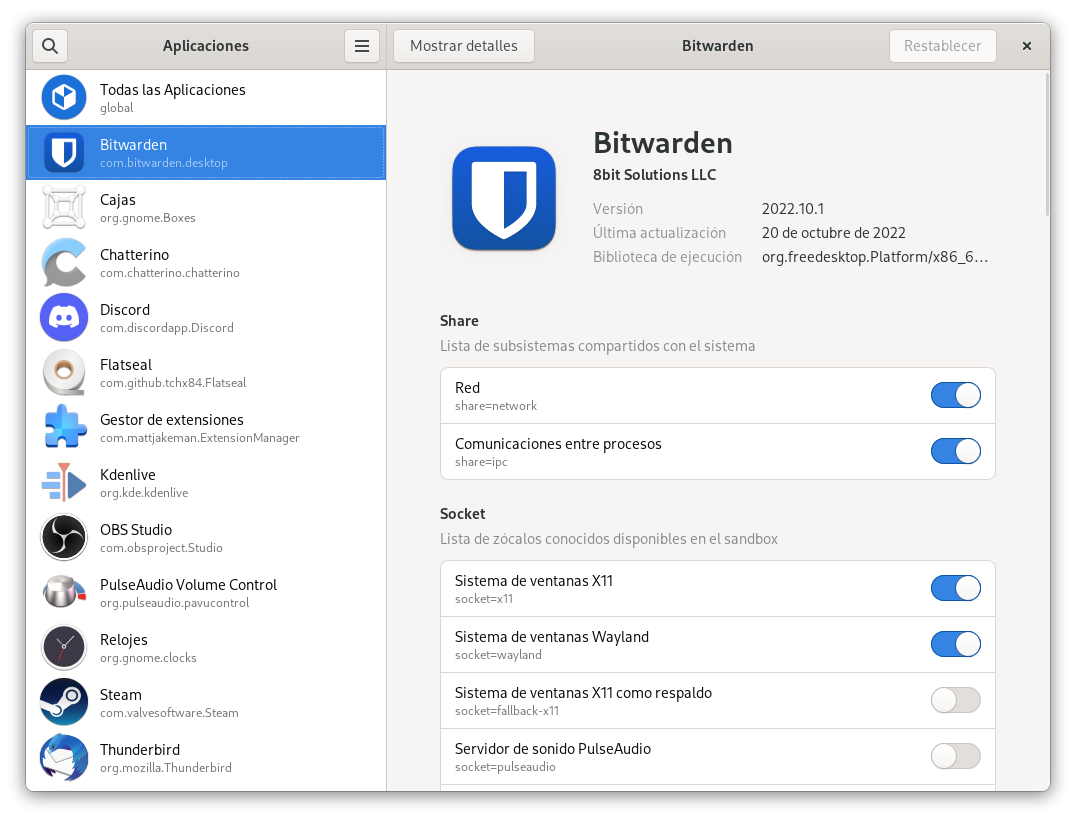
Flatseal: controla los permisos de tus apps Flatpak
Si utilizas con regularidad aplicaciones Flatpak seguramente ya sepas que muchas de estas aplicaciones vienen por seguridad limitadas para que no tengan acceso más allá de donde realmente les haga falta. De este modo, si una aplicación todo lo que va a hacer es mostrar una página web dentro de algún tipo de ventana Electron,
-
Cómo cambiar el tamaño de la swap de Linux
Cómo crear un archivo swap para poder cambiar su tamaño una vez que ya hemos formateado el ordenador.