En Bluesky no existe en este momento nadie que se ocupe de repartir marcas de verificación a las cuentas que sean oficiales, como las de X/Twitter o Instagram. Sin embargo, es posible saber si una cuenta es oficial o una imitación mirando su nombre de usuario.
En Bluesky, es posible tener un identificador de usuario que termine en .bsky.social. Pero, si tienes un sitio web, puedes cambiar tu identificador por el nombre de esa web. Bluesky entonces verifica que seas la persona propietaria de ese sitio web. Por lo tanto, se puede asumir que si un identificador de Bluesky es un dominio propio, entonces es que la persona que controla esa cuenta es la misma que la que controla esa página web.
Cómo funcionan las cuentas verificadas en Bluesky
Por ejemplo, la cuenta de Bluesky de El Mundo Today es @elmundotoday.com. Como esa cuenta se llama igual que la web donde publican sus noticias, sabemos que es la oficial. Sabemos que @bsky.app es la cuenta oficial de Bluesky porque su nombre de usuario es el de la propia web a la que entras para publicar posts.
Otro ejemplo es @20minutos.es. Es la cuenta oficial porque su nombre de usuario es la URL de su periódico. La única forma de que hayan podido hacer eso es teniendo el control de la página web. ¿Será @eldiarioes.bsky.social la cuenta oficial de eldiario.es, o será una imitación que habrá configurado alguien? No se sabe en este momento; tal vez si cambiasen el nombre de usuario por @eldiario.es lo podríamos saber. Actualizo: el handle ahora es @eldiario.es, así que ahora sí están verificados y sabemos que son ellos.
Yo no puedo poner mi cuenta de Bluesky como @wikipedia.org, porque la única forma de hacer eso es haciendo un ajuste al sitio web o al dominio wikipedia.org para probar que controlo esa página web, cosa que lógicamente no ocurre, por lo que no es posible simplemente ponerme ese nombre de usuario.
Aun así, hay mucha gente que utiliza igualmente Bluesky pero que no sabe que puede hacer este cambio. Si tienes otra forma de verificar de forma externa que una cuenta terminada en .bsky.social es tuya (por ejemplo, porque lo diga en otra red social o en su página web), de algún modo eso también lo confirma.
De todos modos, hacer el cambio, si posees un dominio porque ya tengas una web o un sistema de correo, y sabes qué botón debes tocar, es muy sencillo y te toma cinco minutos.
Cómo verificar la cuenta de Bluesky
Primer paso: necesitas tener un dominio. Si ya tienes un blog o una página, esto es fácil. Si no, primero deberás obtener uno. Esto cuesta dinero porque los dominios hay que renovarlos periódicamente. Hay dominios más caros y dominios más baratos. Mi experiencia con los dominios regionales «normales» (por ejemplo, .es) es que suelen ser baratos. Algunos .com también pueden serlo. Los dominios «modernos» como .dev, .rocks, .gay, también son otra opción que puede darle más personalidad a tu dominio pero a menudo esconden costos de renovación más caros, así que plantéatelo bien. Si no tenías una web hasta el momento y consideras que no es relevante para ti pagar por una sólo para esto, supongo que hasta aquí has llegado.
Hecho eso. Para poder verificar que controlas ese dominio, vas a tener que hacer una de las dos cosas siguientes. Cuál elijas depende de tus habilidades.
- Una opción es ir a las opciones de DNS de tu dominio y agregar un código que Bluesky te va a proporcionar. Tal vez sepas administrar sitios web y prefieras usar la verificación por DNS. Es la forma más limpia porque no te obliga a modificar tu página web o incluso a crear una.
- Otra opción es cargar un archivo en tu sitio web, que tiene que estar en una ruta concreta. Tal vez no controles la DNS, o no sepas hacerlo y no tengas nadie a quien puedas pedir ayuda, y prefieras cargar un archivo en una ubicación concreta de tu página usando un mísero FTP o instalando NGINX o Apache en tu VPS, por ejemplo.
Voy a hacer un ejemplo con este blog para mostrarte los pasos. Supongamos que quiero cambiar mi identificador de cuenta por @nosgustalinux.es para probar que mi cuenta de Bluesky es la oficial.
Ve a los Ajustes, y desde ahí localiza la sección Cambiar nombre de usuario. Desde ahí, haz clic en el enlace «Tengo mi propio nombre de usuario».
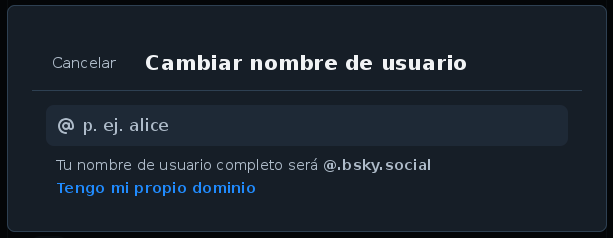
Ahí verás una pantalla un poco técnica. En primer lugar, pon el nombre de tu dominio en la parte de arriba, donde dice «Introduce el dominio que quieres utilizar». Y después, elige una de las dos formas de verificar tu cuenta.
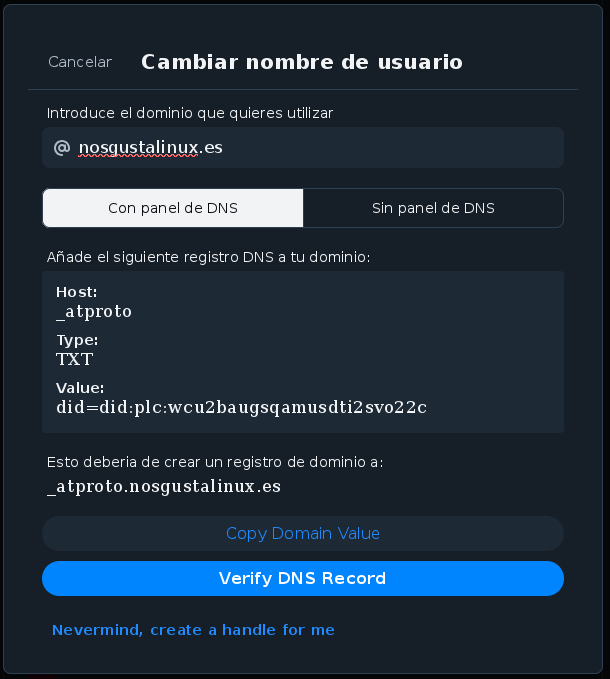
Si sabes usar las opciones de DNS de tu sitio web, puedes entrar en el panel de control del lugar donde hayas contratado el dominio, y agregar un nuevo dominio de tipo TXT que se llame _atproto. Ponle como valor lo que ves en la pantalla, ese código especial que empieza por did=did:plc:. Aquí depende mucho de cada proveedor, así que consulta la ayuda en tu proveedor si no sabes cómo llegar a esa pantalla.
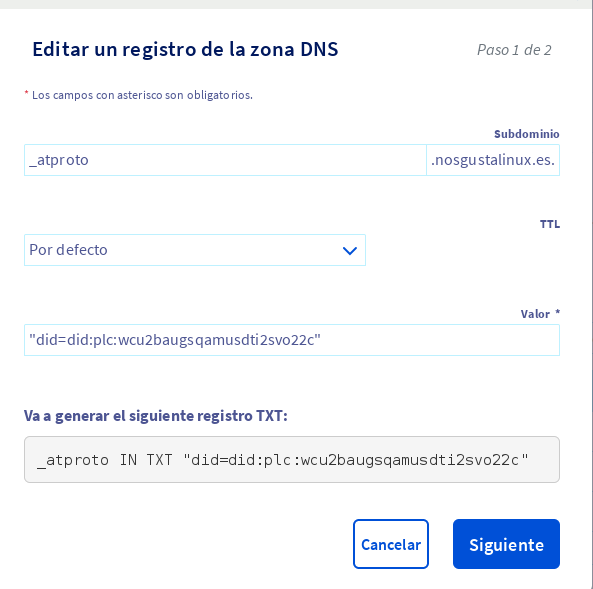
Una vez hayas creado esa entrada en la DNS de tu dominio, espera uno o dos minutos para que propague bien, y luego pulsa el botón «Verify DNS record» en Bluesky. Deberías ver el mensaje «¡Dominio verificado!», que te indica que todo se ha conectado bien. Confirma de nuevo, y con eso habrás cambiado tu identificador de usuario.

Si, por lo que sea, no tienes forma de entrar en las opciones de DNS de tu dominio (o no las hay, por ejemplo, GitHub Pages o GitLab Pages), puedes pulsar el botón Sin panel de DNS y seguir los pasos que te indican ahí. En este caso, tendrías que crear un archivo en tu página web que sea visible desde la URL que te indican, y cuyo contenido sea lo que te piden que tenga. Si puedes crear archivos en tu web, será que es tuya, así que es un proceso de verificación válido.
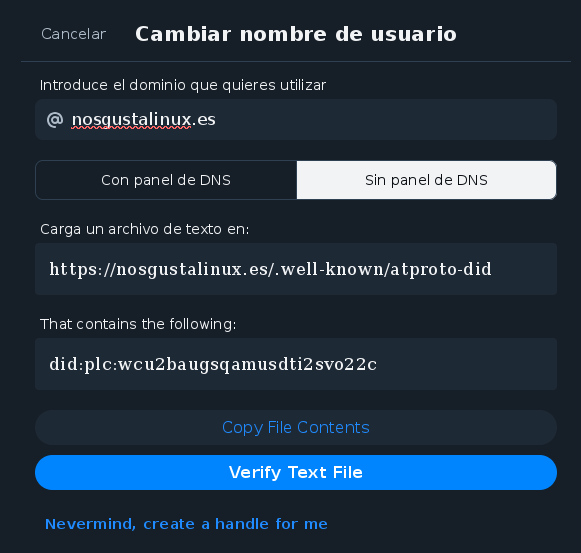
Una vez que hayas creado ese archivo, visita la URL en tu navegador, comprueba que puedes ver el valor, que tiene que tener una forma como did:plc: y un código de números y letras, y de ser así, pulsa el botón de verificar para comprobar tu identidad.
Ten en cuenta que Bluesky podría verificar periódicamente tu identidad, así que no recomendaría que quitases el archivo ni que borrases el registro DNS, por lo que pudiese pasar.